强化学习有三大算法:①动态规划DP:环境模型已知;②蒙特卡洛MC:模型环境未知,有确切结束条件的博弈;③时序差分TD:模型环境未知,无需有确切结束条件,这里是蒙特卡洛树搜索。
1 问题描述
本题目中黑白棋的规则为:在8×8的棋盘上,初始各有两个黑白棋子。
- 新落下的棋子必须落在可夹住对方棋子的空位上,夹住的位置必须全部是对方的棋子,不能有空格;被夹住的对方棋子翻转为本方的棋子。
- 如果一方没有合法棋子可下则弃权,直到有合法棋子可下;
- 直到棋盘填满或者双方都无合法棋子可下结束
- 如果有一方落子时间超时或者连续三次下到非法位置,则这一方失败
可见每一方下棋时的可行动的选择是有限的,理论上可以构建出一棵巨大的博弈树,包含所有的结果,似乎可用极大极小算法+(MAX方棋数量-MIN方棋数量)作为评估函数来得到最佳的选择行动,但是这种算法是基于对方也按照每一步都最有利于他的策略行动而设计的,如果对方是完全随机行动或者说没有选择最优策略,就不合适了。所以我们需要实时根据对方已经行动后的棋盘,选出使得平均收益最大的行动。
2 设计思想
蒙特卡洛树搜索算法:在每一次进行抉择时,都会进行一次搜索,是实时动态的,而非是极大极小那样先搜索完再执行的。本质是靠不断模拟运行加反向更新来评判各个选择的优劣的。
蒙特卡洛树搜索是一个迭代的过程,每一次完整的迭代包括四个过程:
- 选择:从根节点开始,向下递归选择子节点,直到达到叶子节点或者还有未拓展的子节点的节点上时停止
- 拓展:如果选择到的节点不是一个叶子节点,即还存在可拓展的子节点,则随机拓展一个未被拓展过的子节点M
- 模拟:从最新拓展的这个子节点M开始,接下来双方持续进行随机决策对弈直到对局结束
- 反向传播:用对局结束得到的分数将M节点及其以上历经的节点进行访问次数更新和奖励值更新
为了防止迭代过程中算法始终按照一条固定的经验路线运行,选择时所用的算法尤为重要,其选择要平衡先前的经验和随机探索
选用
$$
UCT(v_i)=\frac{w_i}{n_i}+c\sqrt{\frac{lnN_i}{n_i}}
$$
$v_i$是待评估的子节点
$n_i$是此节点的被访问次数
$N_i$是其父节点的被访问次数
c是探索常数,一般取$\sqrt2$
$w_i$是此节点的累积奖励
前面一项表示先前的经验,后面一项表示探索,当$n_i$较小时探索项会增大,会促使算法探索新的节点
在选择的过程中,先按照UCT评估每个子节点的值,然后再选择最大的子节点
反向传播时的奖励值可以用模拟对局结束时的棋子差值,胜利用+diff,失败用-diff
3 代码实现
已经给出了封装好的broad类和game类
broad类主要用到了如下方法
1
2
3
4
| _move(action, color)
get_legal_actions(color)
get_winner()
|
首先定义节点及相关方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| class Node:
def __init__(self, state, color, parent=None, move=None):
self.state = state
self.color = color
self.parent = parent
self.move = move
self.children = []
self.visits = 0
self.wins = 0
self.untried_moves = list(state.get_legal_actions(color))
def ucb1(self, c=math.sqrt(2)):
if self.visits == 0:
return float('inf')
return (self.wins / self.visits) + \
c * math.sqrt(math.log(self.parent.visits) / self.visits)
def best_child(self, c=math.sqrt(2)):
best = None
best_value = -float('inf')
for child in self.children:
uct_value = child.ucb1(c)
if uct_value > best_value:
best_value = uct_value
best = child
return best
|
然后在AIPlayer类中:
定义对局结束判断函数
1
2
3
4
| def _is_terminal(self, board):
return (not list(board.get_legal_actions('X')) and
not list(board.get_legal_actions('O')))
|
定义蒙特卡洛树搜索算法:
1
2
3
4
5
|
while not node.untried_moves and node.children:
node = node.best_child()
state._move(node.move, current_color)
current_color = 'O' if current_color == 'X' else 'X'
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
if node.untried_moves:
move = random.choice(node.untried_moves)
state._move(move, current_color)
next_color = 'O' if current_color == 'X' else 'X'
child = Node(deepcopy(state),
next_color,
parent=node,
move=move)
node.children.append(child)
node.untried_moves.remove(move)
node = child
current_color = next_color
|
1
2
3
4
5
6
7
|
while not self._is_terminal(state):
legal = list(state.get_legal_actions(current_color))
if legal:
state._move(random.choice(legal), current_color)
current_color = 'O' if current_color == 'X' else 'X'
|
1
2
3
4
5
6
7
8
9
10
11
12
|
winner, diff = state.get_winner()
while node is not None:
node.visits += 1
if winner == 2:
pass
elif (winner == 0 and self.color == 'X') or \
(winner == 1 and self.color == 'O'):
node.wins += diff
else:
node.wins -= diff
node = node.parent
|
总流程(四个步骤已忽略)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| def get_move(self, board):
print("请等一会,对方 {}-{} 正在思考中...".format(
'黑棋' if self.color == 'X' else '白棋', self.color))
root = Node(deepcopy(board), self.color)
if not root.untried_moves:
return None
for _ in range(200):
node = root
state = deepcopy(board)
current_color = self.color
best_action = max(root.children, key=lambda c: c.visits).move
return best_action
|
4 实验结果
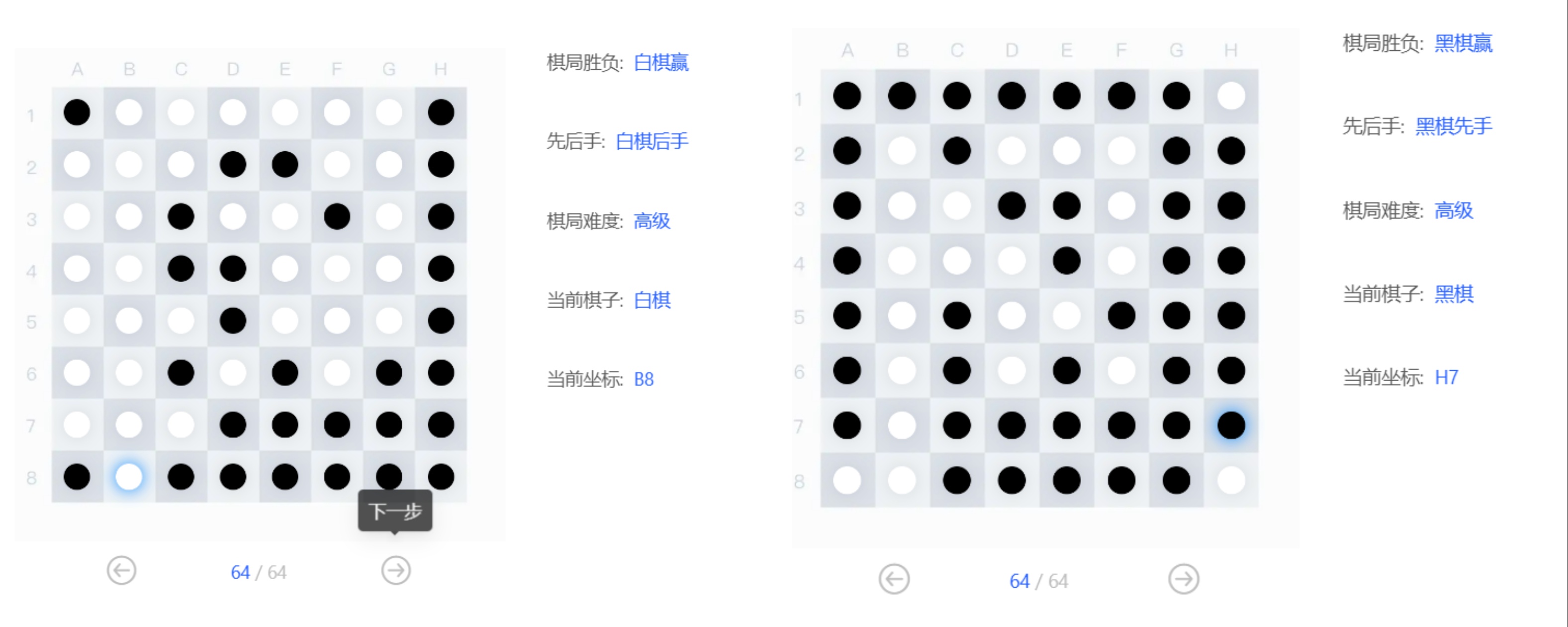
和人类对战以及和随机行动机器人对战的结果


测试时和高级对战时结果为
5 总结
实验已基本完成预期目标,能够和高级AI对弈并获胜,只是测试时发现有时还是会输,这个可以通过提高迭代次数来提高性能,注意有1min超时的限制,迭代次数不要太多防超时。
迭代次数改为800,结果确实更好了